Using GitLab CI/CD to automate my Packer builds

The “CI” part of CI/CD stands for “Continuous Integration”, but it could easily stand for “Continuous Improvement”. Aside from being a concept familiar to anyone who has read “Atomic Habits”, continually improving something can be a good thing as long as you don’t take it to extremes and recognise when the investment of effort is greater than the return.
This has been mostly true of my Packer build repository. It fulfilled my needs and it was reusable. I was able to facilitate a degree of automation by combining some of the features of VMware Aria Automation (the SaaS version) with my repository in Github.
Any changes that I pushed to the repository would use a webhook to trigger a Packer build in the Pipelines component of Aria Automation. I could also execute builds on demand. Aside from regular maintenance, like using newer ISO images, I didn’t have to change much. As I said, it fulfilled my needs.
But a few things have changed…
The biggest challenge that came up was that VMware announced the End of Availability (EoA) of the Aria SaaS services as of February 2024. That started the clock ticking on the cloud organization that I was using and prompted me to bring Aria Automation back into my Homelab. This then prevented me from using a Github webhook to trigger my Packer pipeline without opening up Aria Automation to the internet (which is not a good idea).

Of course, I could simply have swapped Github out for GitLab inside my Homelab. The same pipeline would work. But I didn’t…
I still like Aria Automation and the Pipelines component is underrated and under used in my opinion. But, other CI/CD solutions exist and I settled on GitLab’s capabilities because I was deploying GitLab anyway (in Kubernetes no less, but that’s a story for another day) and because my good friend Mark Brookfield had already put together a pipeline to do much of what I wanted.
(Update 26/03/2026: The Pipelines component is deprecated in VCF Automation 9.x.)
You can read his original article here: Using GitLab CI/CD Pipelines to Automate your HashiCorp Packer Builds.
New Solution
Right, are you strapped in tight? Let’s go!
Packer Changes
I actually had to make no changes to my Packer repository. Each build, each guest OS type and version was already split out into its own folder and I long ago did the work of separating the code from the configuration.
By that I mean that the Packer templates have little configuration in them. Anything that’s OS specific is contained within a separate variables file for each template. Anything environment specific isn’t in the template at all, those values are “injected” during the build process. An example might help here, take my Ubuntu 24.04 template:
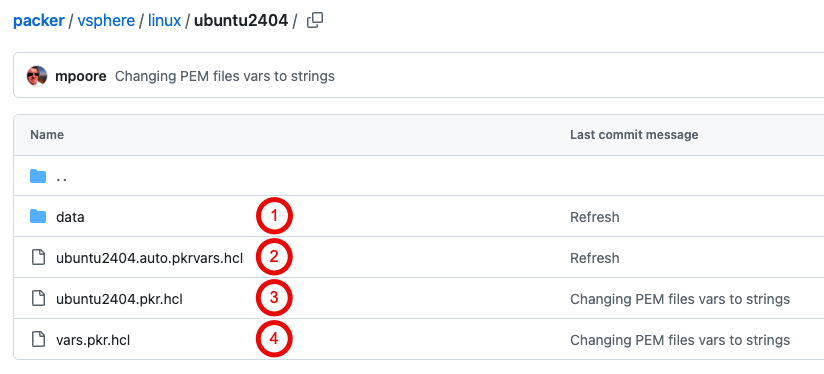
- The data folder contains a file called “user-data” that is used to enable an automated installation of Ubuntu. There are some settings in this file that can be modified by Packer. The values for those settings are held in the next file below.
- The pkrvars file contains OS-specific values for certain build options. For example, the hardware version used to create the VM when Packer executes, and the name of the ISO file that is used to install Ubuntu.
- This is the main Packer template. Most of the settings have values supplied from variables rather than being set directly. Those values either come from the file above or are “injected” as part of my automated process.
- The vars file contains definitions for all of the variables used. What type they are and a description of what they’re for.
As I’ve already said, there were no changes that I had to make here. I made a few small tweaks based on my past experiences, but nothing material.
Repository Changes
My Github repository for Packer templates was the single source of truth and also publicly shared. I wanted to keep it shared but I was willing to demote its role a bit. What I have settled on now is best shown diagrammatically.
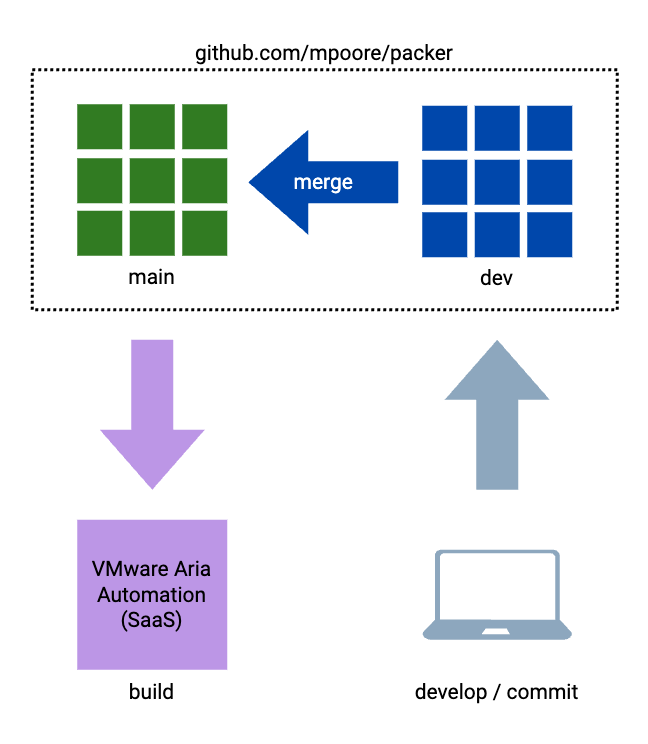
The above arrangement was quite simple. I would develop the builds on my laptop and commit them to the dev branch of my public Packer repository in GitHub. Following a merge request (because the main branch is protected), a webhook would trigger build execution in VMware Aria Automation. What I have now is fractionally more complex, but mostly because I wanted my repository to be publicly shared still.
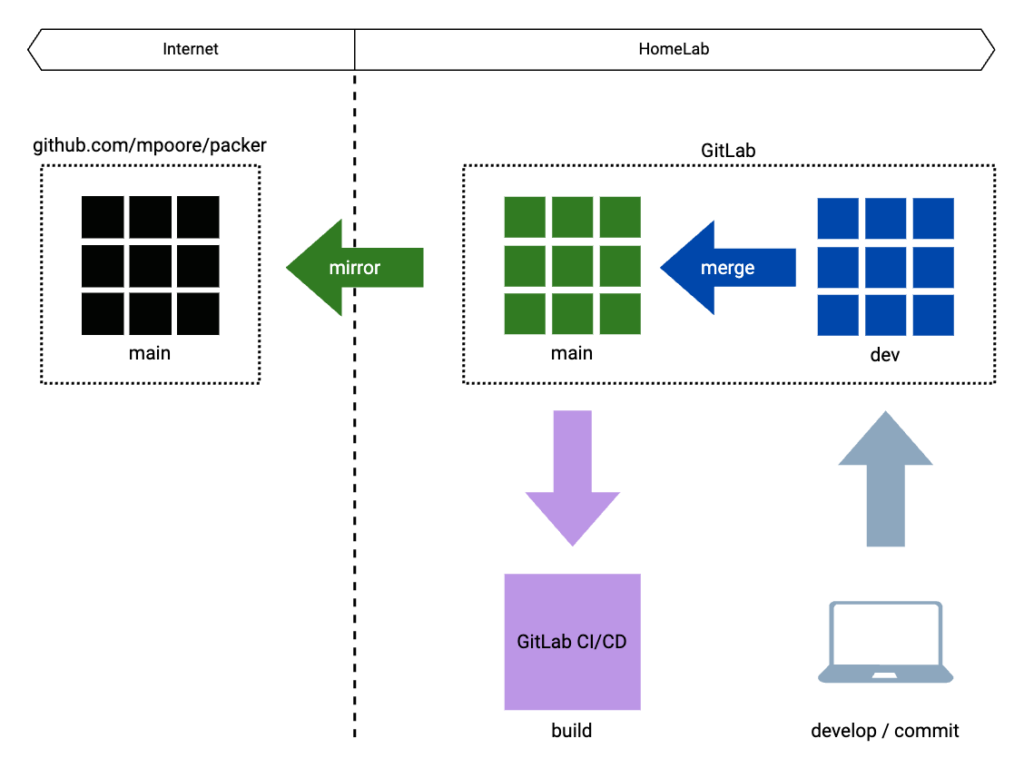
This new arrangement has some similarities to the original. The same two branches are used, main and dev. When changes are merged into the main branch in GitLab though, it is a GitLab runner and a CI/CD pipeline that is executing the Packer builds. All of this takes place within the perimeter of my HomeLab. So that all changes and developments are still available publicly, the main branch is mirrored to the original GitHub repository automatically.
Process Changes
The repository changes that I’ve outlined above also cover off the high-level process changes that have taken place. However, it is the detail that we’ll focus on more here.
GitLab Pipeline
I spent a little while making some changes to the original pipeline that I took from Mark’s post. I wanted it to build my Packer templates on a schedule, or if a merge request completed. Additionally, when a merge request was made I only wanted the changed builds to be executed, not the whole lot. What I ended up with can be seen below (and in the repository):
workflow:
rules:
- if: $CI_COMMIT_MESSAGE =~ /See merge request/
- if: $CI_PIPELINE_SOURCE == 'schedule'
- when: never
stages:
- init
- build
image: alpine
before_script:
- apk add xorriso git
- export PKR_VAR_vcenter_username="$vcenter_username"
- export PKR_VAR_vcenter_password="$vcenter_password"
- export PKR_VAR_admin_password="$admin_password"
- export PKR_VAR_build_username="$build_username"
- export PKR_VAR_build_password="$build_password"
- export PKR_VAR_build_password_encrypted="$build_password_encrypted"
- export PKR_VAR_rhsm_user="$rhsm_user"
- export PKR_VAR_rhsm_pass="$rhsm_pass"
- export PKR_VAR_vcenter_server="$vcenter_server"
- export PKR_VAR_vcenter_datacenter="$vcenter_datacenter"
- export PKR_VAR_vcenter_cluster="$vcenter_cluster"
- export PKR_VAR_vcenter_folder="$vcenter_folder"
- export PKR_VAR_vcenter_datastore="$vcenter_datastore"
- export PKR_VAR_vcenter_network="$vcenter_network"
- export PKR_VAR_vcenter_iso_datastore="$vcenter_iso_datastore"
- export PKR_VAR_vcenter_content_library="$vcenter_content_library"
- export PKR_VAR_root_pem_files="$root_pem_files"
- export PKR_VAR_issuing_pem_files="$issuing_pem_files"
get_packer:
stage: init
artifacts:
paths:
- packer
script:
- echo "Fetching packer"
- wget https://releases.hashicorp.com/packer/1.11.2/packer_1.11.2_linux_amd64.zip
- unzip packer_1.11.2_linux_amd64.zip
- chmod +x packer
rules:
- if: $CI_COMMIT_REF_NAME == 'main'
scheduled_packer_build:
stage: build
script:
- echo "Scheduled build of $BUILD, proceeding.";
- ./packer init $BUILD;
- ./packer build $BUILD
parallel:
matrix:
- BUILD:
- vsphere/linux/centos9
- vsphere/linux/photon4
- vsphere/linux/photon5
- vsphere/linux/rhel8
- vsphere/linux/rhel9
- vsphere/linux/ubuntu2404
- vsphere/windows/win2019
- vsphere/windows/win2022
rules:
- if: $CI_PIPELINE_SOURCE == 'schedule' && $CI_COMMIT_REF_NAME == 'main'
merge_packer_build:
stage: build
script:
- |-
if (git diff --name-only $CI_COMMIT_SHA~ $CI_COMMIT_SHA | grep -q "^$BUILD/"); then
echo "Changes detected in $BUILD, proceeding with build.";
./packer init $BUILD;
./packer build $BUILD
else
echo "No changes in $BUILD, skipping build.";
exit 0;
fi
parallel:
matrix:
- BUILD:
- vsphere/linux/centos9
- vsphere/linux/photon4
- vsphere/linux/photon5
- vsphere/linux/rhel8
- vsphere/linux/rhel9
- vsphere/linux/ubuntu2404
- vsphere/windows/win2019
- vsphere/windows/win2022
rules:
- if: $CI_PIPELINE_SOURCE == 'push' && $CI_COMMIT_REF_NAME == 'main'- 1-5: These rules apply to the whole pipeline. The rule on line 3 ensures that the pipeline is triggered by a merge request (apparently that’s the commit message that GitLab uses), or via a scheduled execution. The “never” on line 5 should stop the pipeline running if neither of those two conditions are met.
- 7-9: Defines the two stages of the pipeline.
- 11: This is the container image that I’ll use.
- 13-32: These commands are executed in the container before anything else happens. On line 14 we add the xorriso and git packages as they’re not present by default. The other lines create environment variables in the container for all of the environmental and sensitive values that I don’t want to make public in the repository.
- 34-45: This job (“get_packer”) downloads and unzips the Packer executable. The rule on line 45 ensures that the job is only run for the main branch in the repository.
- 47-65: This job executes scheduled Packer builds. The script that is run (lines 50-52) is pretty simple. The packer init command verifies the template an installs any necessary plugins. The packer build command does the hard work! The script is execute once for each of the builds listed in lines 56-63, which results in a copy of the job for each build. Finally, on line 65, we have a rule that ensures that this set of jobs only executes for scheduled builds on the main branch.
- 67-91: Similar to the job above, but this one is a little more complex. A copy of the job is created for each build in lines 82-89, but there’s more to the script steps. The if statement evaluates the commit that is triggering the pipeline execution to see if any changes have been made to the build in question. If so, then Packer executes. Otherwise it skips the build as there are no changes. Once again, on line 91, we limit when this job will run.
Including the pipeline’s YAML in the repository is all that is needed for GitLab to pick it up and using it, when it’s allowed! However, to schedule the pipeline for regular execution requires creating a pipeline schedule, but this is almost child’s play!
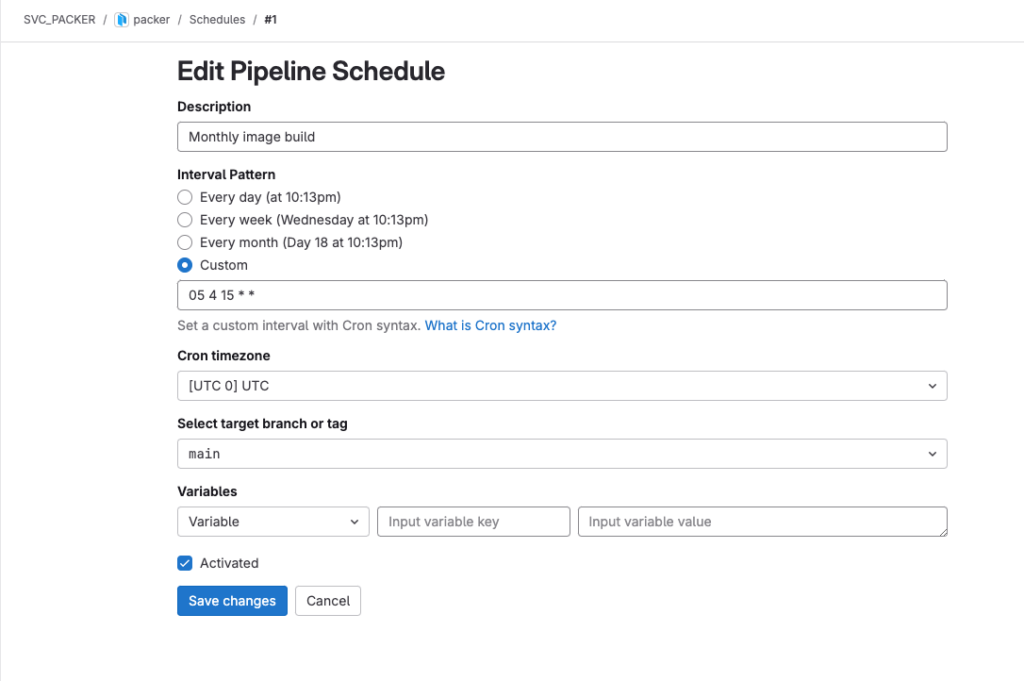
GitLab CI/CD Variables
The last major puzzle piece is getting environmental and / or sensitive values into the pipeline execution. The pipeline may create these for our jobs, but we still need to enable the pipeline to get these values from somewhere. Ideally I would use external secrets and put the values in Vault, but at the time of writing I haven’t got that working. Instead, the repository in GitLab can have CI/CD variables defined. For the time being this was sufficient for me.
As I started about entering the variables and their values though, I discovered some odd behaviour that I haven’t been able to explain. The CI/CD variables can have certain properties set on them that controls how they are treated by pipelines. Those properties are:
- Visibility – A variable is either Visible, so it can be seen in the job logs, or it is Masked so that its value is not displayed in the job logs. Hopefully.
- Protection – A variable can be Protected so that it can be exported only to pipelines running on protected branches (like my main branch).
- Expansion – A variable can be Expanded, meaning that the dollar symbol ($) is treated as a reference to another variable.
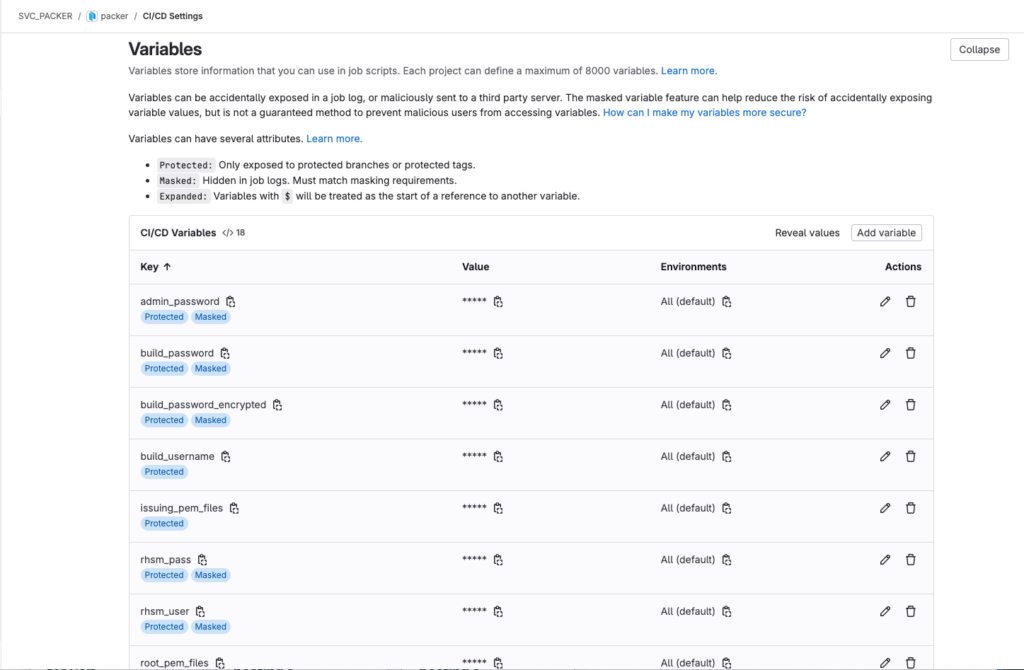
With my variables I opted to have them Protected and Masked. Which was great until I got to my “vcenter_datacenter” variable. I don’t mind revealing the value in this case as it’s not exactly sensitive, it just describes my vCenter environment.
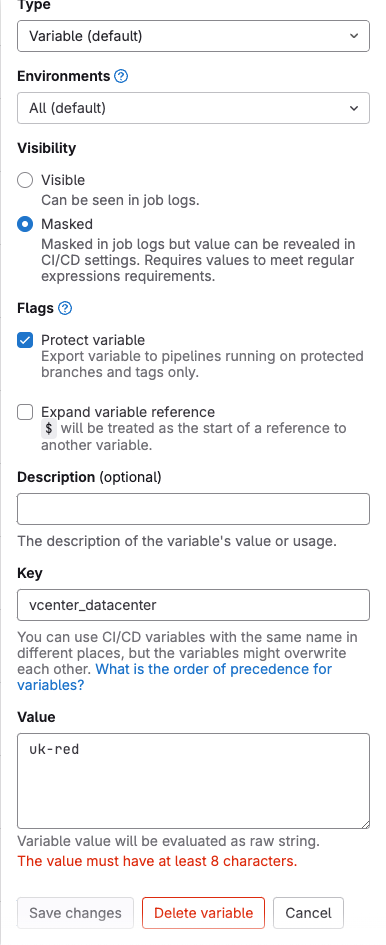
At first I thought that all variables had to have a minimum number of characters. I could have renamed my datacenter but I have other things that use that value and I didn’t want to have to make dozens of changes. I toyed with the idea of hard-coding the datacenter name into my builds or my pipeline, but that made my skin itch to even think about it! Finally, I started messing with the options and I turned off the Masked property for the variable. The warning went away and I was able to create the variable.
There’s probably a reason for that behaviour, but I have no idea what it is!
Summary
With all of these changes, my Packer builds are now executed under one of two different scenarios:
- Every month on the 15th
- After a merge commit to the main repository in Gitlab
This is definitely an improvement!
Photo by Jens Freudenau.


Related Posts